Inside Git: How It Works and the Role of the .git Folder
You've learned the essential Git commands like git add and git commit, but have you ever wondered what magic happens when you type them? Git isn't just a clever file copier; it's a sophisticated content tracker.
Understanding Git's internal mechanics will transform your understanding from simply using Git to truly mastering it. Let's dive into the .git folder and explore the core components that make version control possible.
Understanding the .git Folder: The Heart of Your Repository
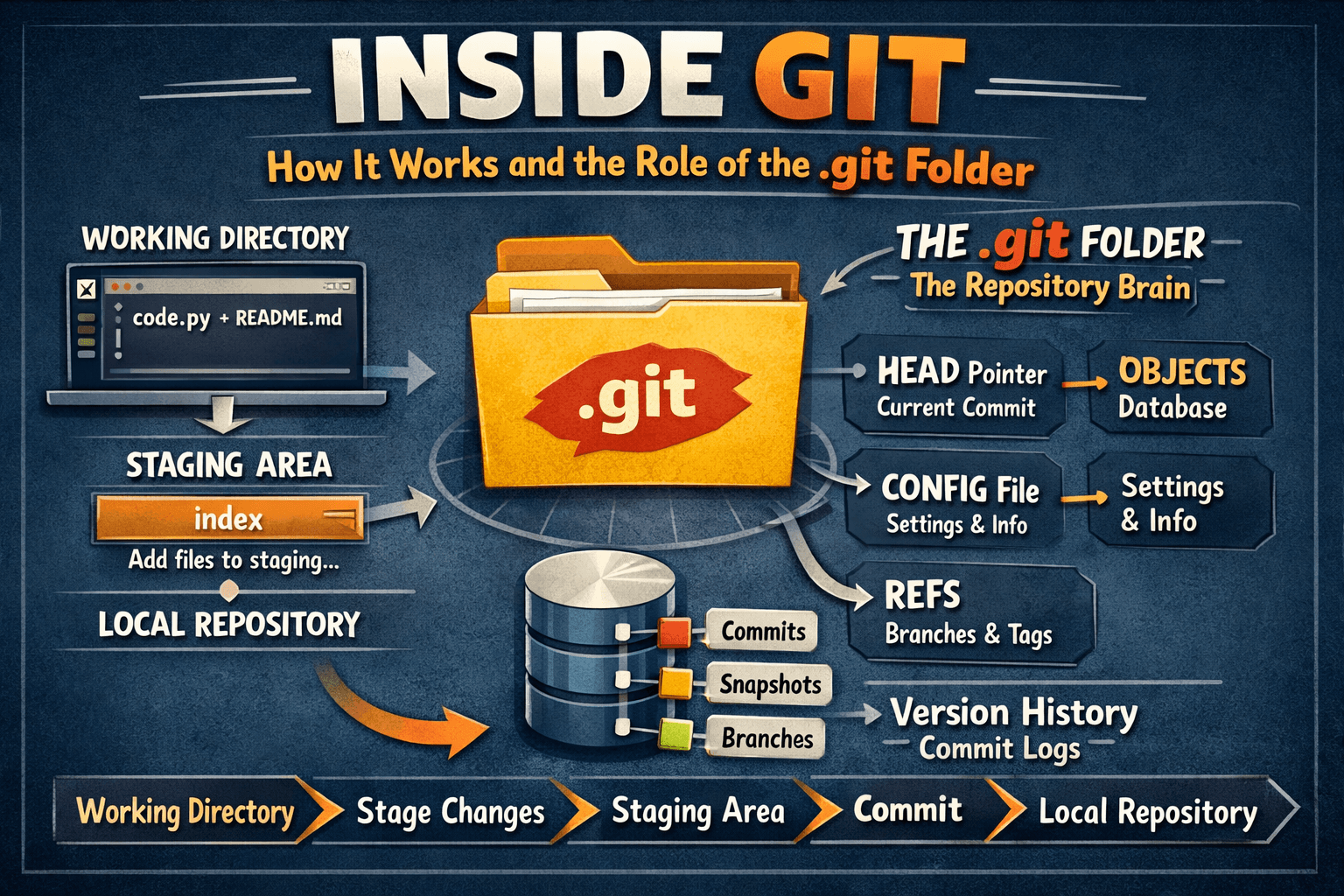
When you run git init in a directory, Git creates a hidden .git folder. This isn't just some metadata; it's the entire Git repository. It contains every piece of information Git needs to track your project's history, perform operations, and maintain its integrity. Without this folder, your project is just a regular directory of files.

Inside .git, you'll find several crucial subdirectories and files:
objects/: This is where Git stores all your content—your files, directories, and commit history—in a highly efficient and unique format.refs/: Contains pointers (references) to commits, such as branches (heads) and tags.HEAD: A special pointer that indicates which branch you are currently on.index: Also known as the "staging area," this file records the content of your working directory that will go into the next commit.
Git Objects: The Building Blocks of Your Project
Git stores everything as one of four core "objects," each identified by a unique SHA-1 hash (a 40-character hexadecimal string). These hashes are crucial for Git's integrity; if even one bit of content changes, its hash changes, meaning Git knows it's a different object.

Blob (Binary Large OBject):
What it is: A blob object simply stores the content of a file. It doesn't contain the filename or any directory structure. If two files have identical content, Git stores only one blob and points to it twice.
Analogy: Think of it as the raw data of your text file, image, or any other file.
Tree:
What it is: A tree object represents a directory. It contains a list of other tree objects (subdirectories) and blob objects (files), along with their filenames, permissions, and hashes.
Analogy: This is like a snapshot of a folder's contents, showing which files are inside and which subfolders exist.
Commit:
What it is: A commit object holds metadata about a specific point in your project's history. It includes:
A pointer to the top-level tree object for that commit (the entire project state).
Pointers to its parent commit(s) (showing its history).
Author and committer information.
Timestamp.
The commit message.
Analogy: A commit is the complete "snapshot" of your project at a moment in time, along with who took the picture and why.
How Git Tracks Changes: git add and git commit Internally
Let's trace the journey of your code when you use the two most common Git commands:

1. git add <file>: Preparing Your Snapshot
When you run git add index.html:
Git takes the current content of
index.html.It calculates a SHA-1 hash for this content.
If a blob object with this content/hash doesn't already exist, Git compresses the content and stores it as a blob object in the
.git/objects/directory.Git updates the staging area (the
indexfile in.git) to record thatindex.html(with its specific blob hash) is ready for the next commit.
2. git commit -m "My commit message": Saving Your History
When you run git commit:
Git looks at the staging area (
.git/index) to see which file contents (blob hashes) are prepared.It then constructs tree objects:
It creates a tree object for each subdirectory, linking to their respective blobs and subtrees.
Finally, it creates a top-level tree object that represents the entire project's directory structure and file contents as they are in the staging area. All these tree objects are stored in
.git/objects/.
Git creates a commit object:
It points to the top-level tree object.
It records the previous commit's hash as its parent.
It adds your author, timestamp, and commit message.
This commit object is also stored in
.git/objects/.
Finally, Git updates the branch pointer (e.g.,
HEADorrefs/heads/main) to point to this new commit object.
This meticulous process ensures that every commit is a complete, immutable snapshot of your project, linked to its parents to form a continuous history.
The Power of Hashes: Integrity and Immutability
Git's reliance on SHA-1 hashes for every object is fundamental to its robustness:
Content Addressable: Git doesn't store files by name; it stores them by their content's hash. This means if you have the hash, you can retrieve the exact content.
Data Integrity: Because the hash is derived from the content, any accidental or malicious alteration of a file or commit would immediately change its hash. Git would detect this discrepancy, guaranteeing the integrity of your history.
Efficiency: If you commit the same file content multiple times, Git only stores the blob once, saving space.
By understanding these internal mechanisms, you gain a powerful mental model of how Git works, helping you troubleshoot issues, understand branching, and appreciate the genius behind this essential tool.


